
![]()
Pogreb is an embedded key-value store for read-heavy workloads written in Go.
- 100% Go.
- Optimized for fast random lookups and infrequent bulk inserts.
- Can store larger-than-memory data sets.
- Low memory usage.
- All DB methods are safe for concurrent use by multiple goroutines.
$ go get -u github.com/akrylysov/pogrebTo open or create a new database, use the pogreb.Open() function:
package main
import (
"log"
"github.com/akrylysov/pogreb"
)
func main() {
db, err := pogreb.Open("pogreb.test", nil)
if err != nil {
log.Fatal(err)
return
}
defer db.Close()
}Use the DB.Put() function to insert a new key-value pair:
err := db.Put([]byte("testKey"), []byte("testValue"))
if err != nil {
log.Fatal(err)
}To retrieve the inserted value, use the DB.Get() function:
val, err := db.Get([]byte("testKey"))
if err != nil {
log.Fatal(err)
}
log.Printf("%s", val)Use the DB.Delete() function to delete a key-value pair:
err := db.Delete([]byte("testKey"))
if err != nil {
log.Fatal(err)
}To iterate over items, use ItemIterator returned by DB.Items():
it := db.Items()
for {
key, val, err := it.Next()
if err == pogreb.ErrIterationDone {
break
}
if err != nil {
log.Fatal(err)
}
log.Printf("%s %s", key, val)
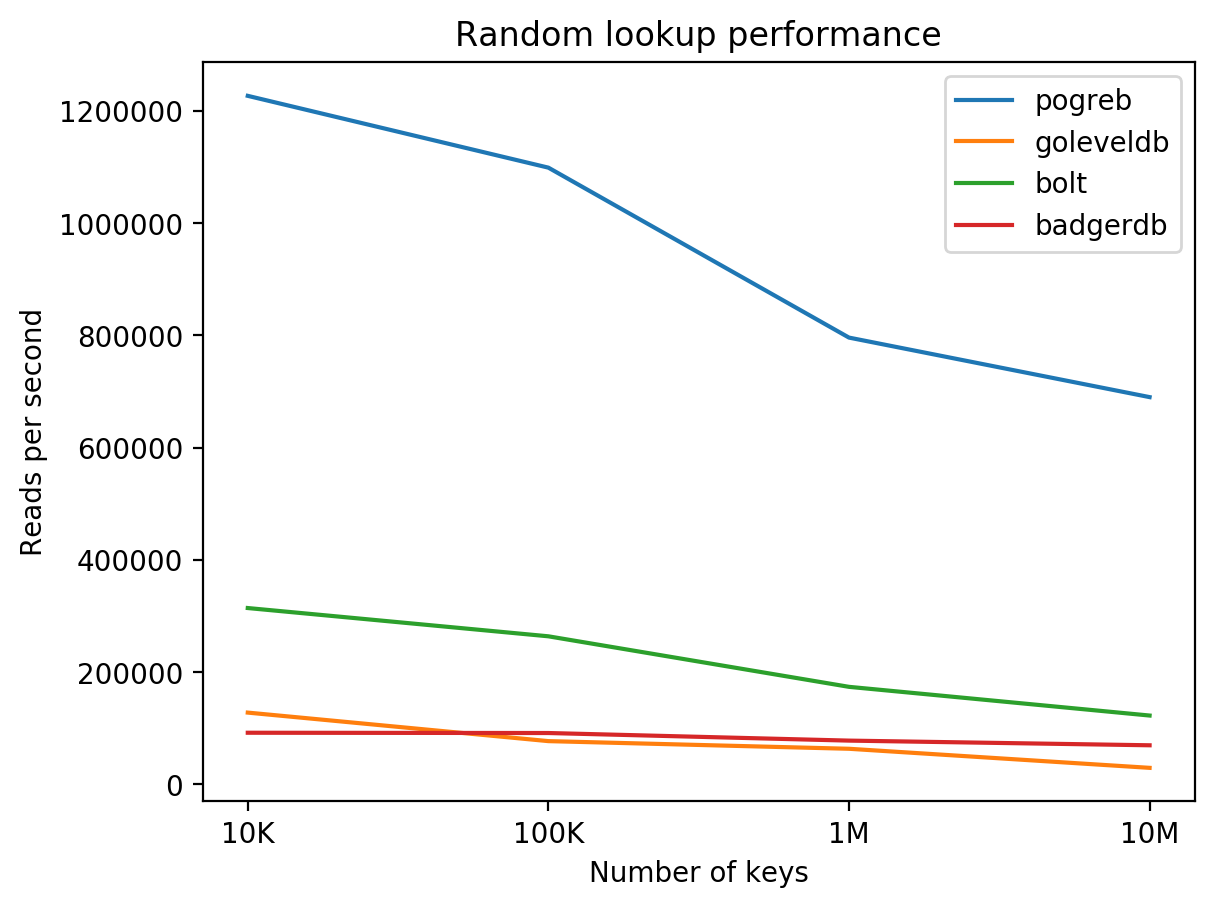
}The benchmarking code can be found in the pogreb-bench repository.
Results of read performance benchmark of pogreb, goleveldb, bolt and badgerdb on DigitalOcean 8 CPUs / 16 GB RAM / 160 GB SSD + Ubuntu 16.04.3 (higher is better):
The design choices made to optimize for point lookups bring limitations for other potential use-cases. For example, using a hash table for indexing makes range scans impossible. Additionally, having a single hash table shared across all WAL segments makes the recovery process require rebuilding the entire index, which may be impractical for large databases.